Why Security Architecture Is Important and How to Implement It

Written by WWC Team


I am currently focused on product ideation and architecture for an early-stage company called Devrev. I have experience in software development and architecture across multiple different domains. Across embedded systems, I've worked on radiofrequency systems for mobile phones and on-prem infrastructure. I have worked in security as well, more from the angle of building a security product at my previous employer, Nutanix. I also work on application software. I have experience working in all sizes of companies, so it's given me an interesting perspective.
When I think about security, I view it from multiple angles. What does it take to develop some of these security solutions? You can potentially build everything from scratch. I know what it takes to build it, I probably wouldn't make that choice for every single one. We have seen news articles about data theft where there's a loss of customer data. Obviously, customers are concerned about this. There's a loss of credibility for the company. There's also the financial loss. We need security to prevent those adverse consequences.
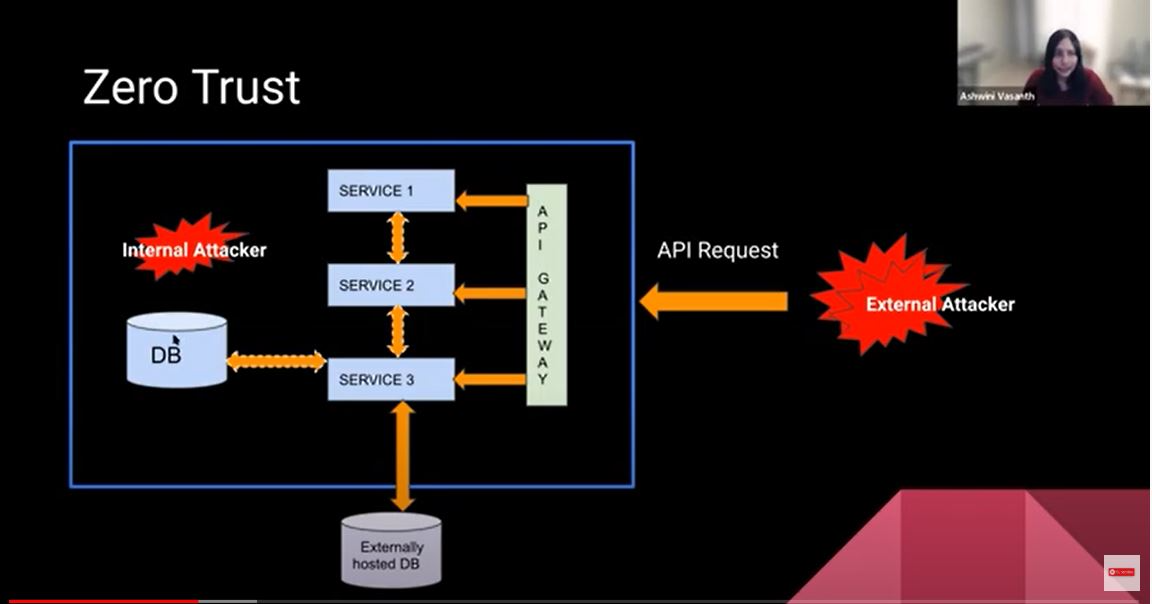
There are various different ways in which you can architect your product, but let’s assume that you have an entry point into your system. That entry point is the API gateway and that's the only piece that is public-facing. You have services and possibly micro-services, which are building out as part of your application, and it's behind the gateway. And then, of course, we would have a database. There are interactions all around. There's one part of the interaction where an API request, or any kind of external interaction that's coming into your product from outside. There are also various interactions that happen within.
The philosophy of zero trust is that we treat everything the same. Treat an attacker who's external as a huge threat and try to secure the boundary. There are various attacks that could actually be internal to your system. Someone could accidentally download a virus that penetrates your entire system and compromises the entire product. Applying the security policies and protocols within and outside the same way, you would be guarding yourself against both.
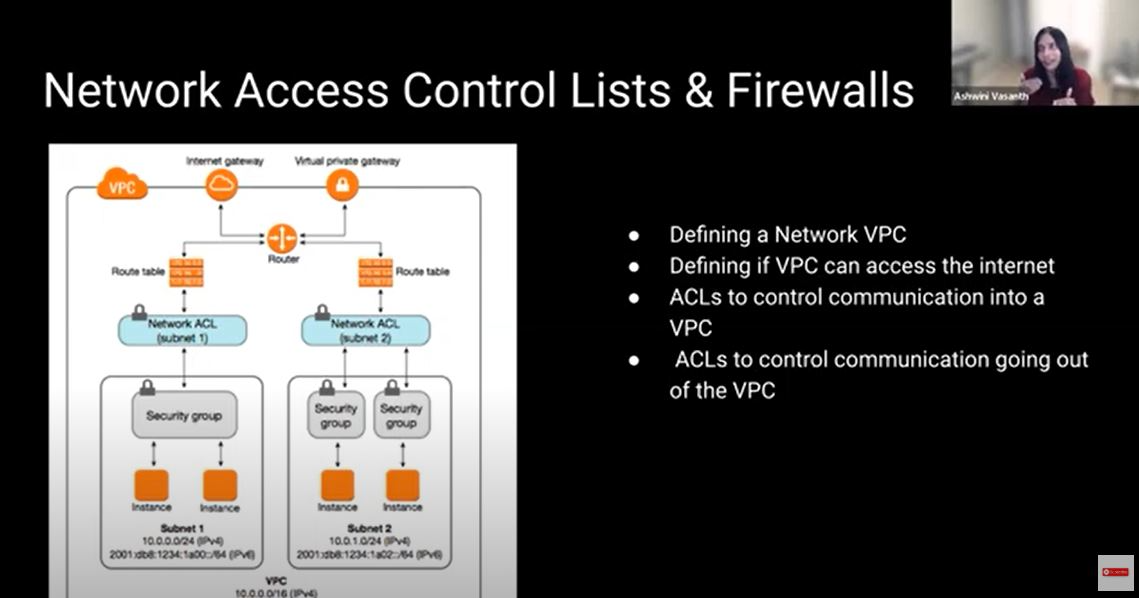
The periphery or the gateway is the fence. There are various levels of protection. The network access control list and the firewall are usually the first levels of defense. The periphery is typically just the entry point into your product, and possibly even outside of your product. It involves a few specialized rules, which are called access control lists. It defines a network boundary. You write rules about what you want to allow access to. It becomes fairly complex because you have to deal with IP addresses and subnets. It's by no means foolproof.
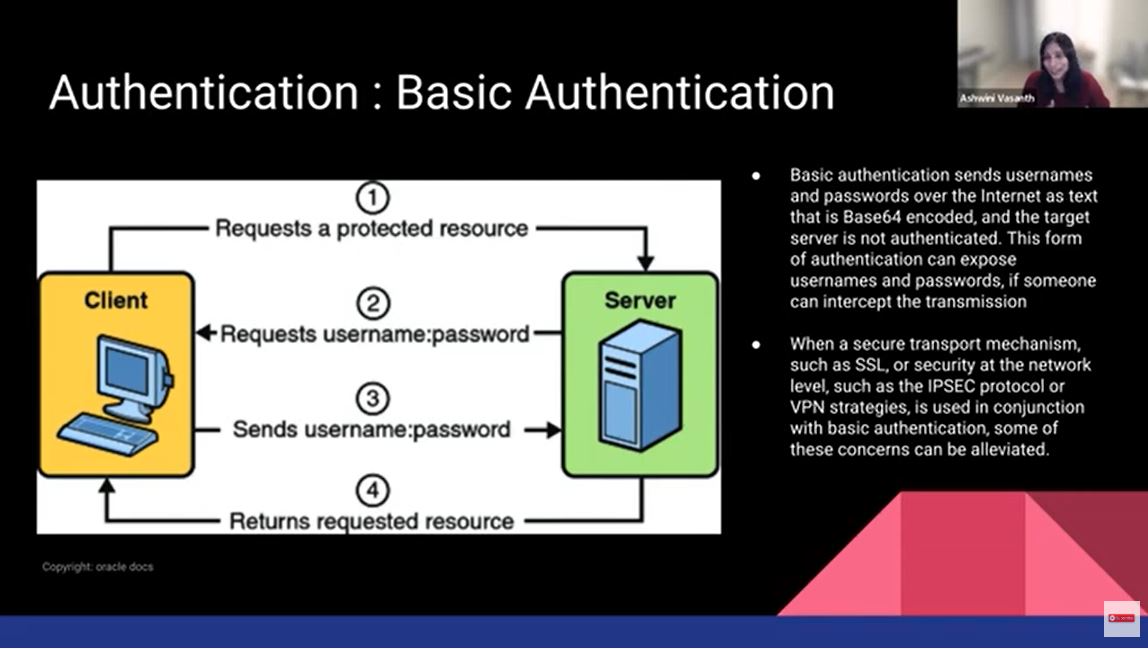
Authentication defines who is trying to gain access. Who are they and what information are they trying to gain access to? There are various different ways of doing authentication. Basic authentication is what most people are familiar with. This is where you give your username and password. It's fairly easy to decode it and figure out how to enter or breach another system. If your medium is actually encrypted, it gives you another level of security.
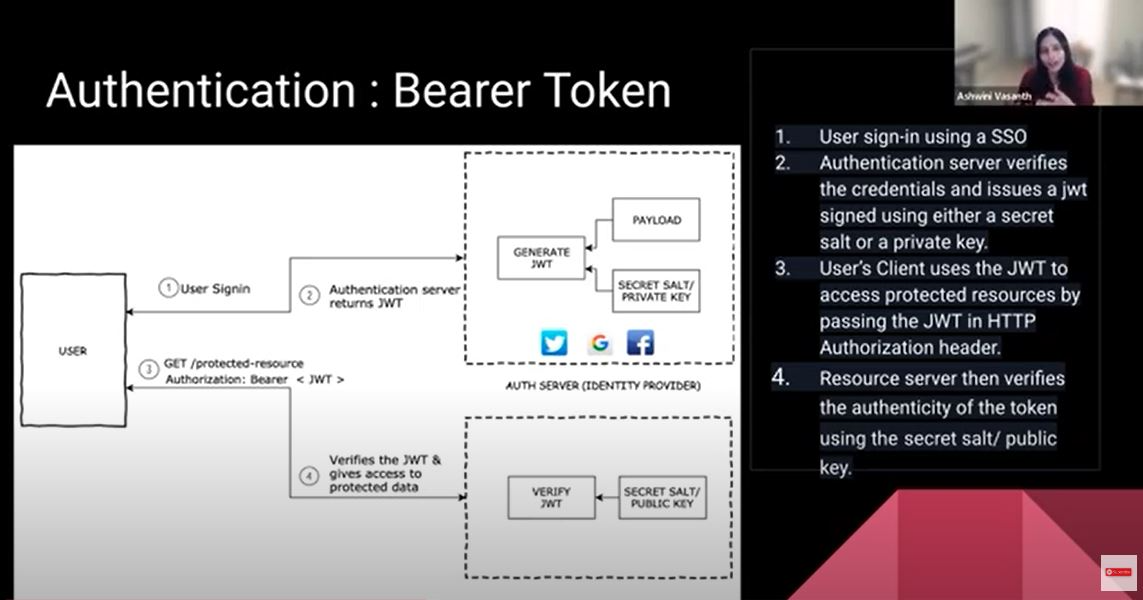
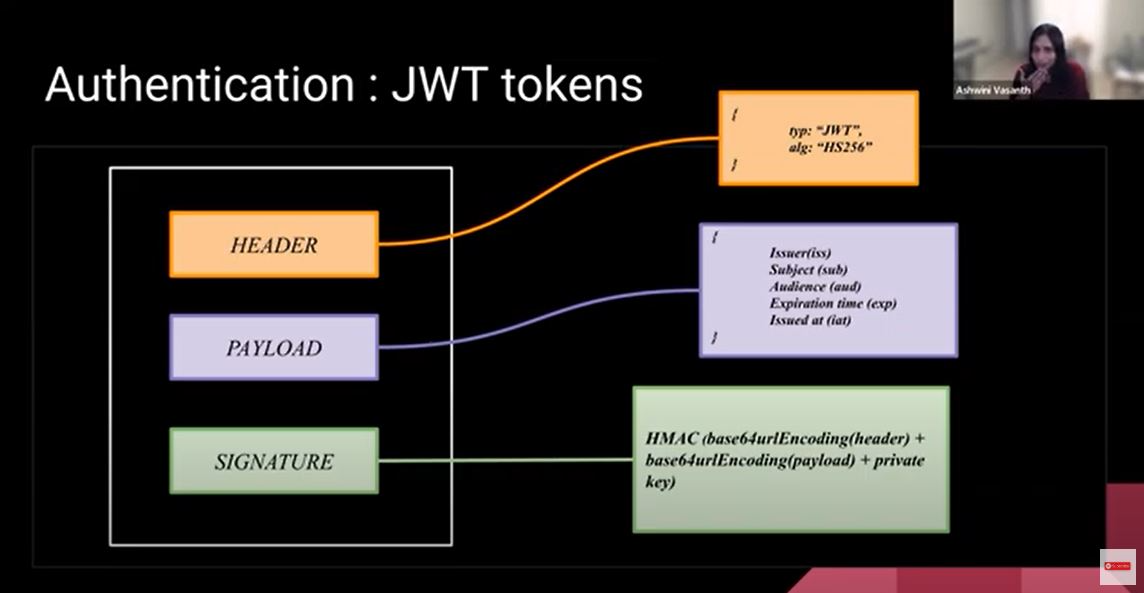
A Bearer Token is kind of a step-up from the username and the password. An identity provider, or an OT Server, generates a token. The bearer of the token is allowed to access the system. The identity provider would generate this token that is unique for each user who's signing in. The token has a header, a payload, and a signature. It will run an algorithm on the header and payload to make sure that it is secure and can be validated. The header will tell the type of token it is. The payload can have custom fields, but it usually has some set fields, like who issued this token, who it is issued for, and how long it allows access. You don't want to put sensitive information within the token that can be easily decoded.

Certificate-based authentication means the webserver trusts something called a certificate authority. An example is we all trust the DMV-issued ID as valid identity proof. The client, when it talks to the server and receives the certificate, is gonna trust that certificate. The certificate is used as a proxy for the server to prove its identity to the client.
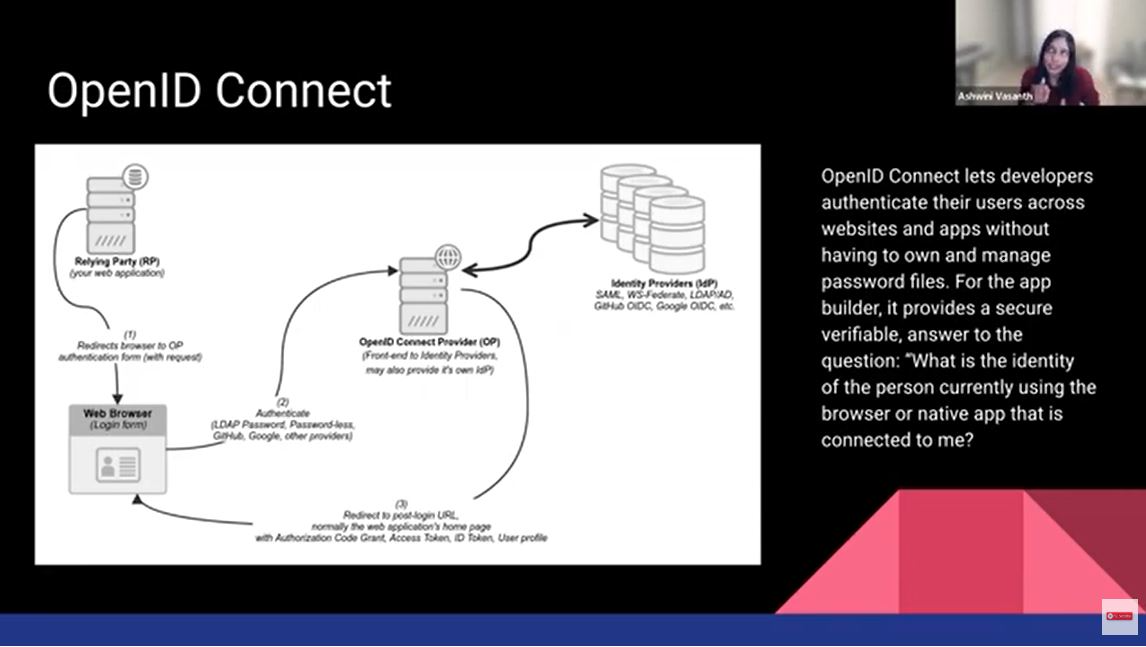
The open ID connect one is probably more current than all of the rest. The way it operates is that your request to the web application actually gets redirected. Many of you have actually encountered this where you will see this login screen where you are redirected to sign on using Google or Facebook, for example.
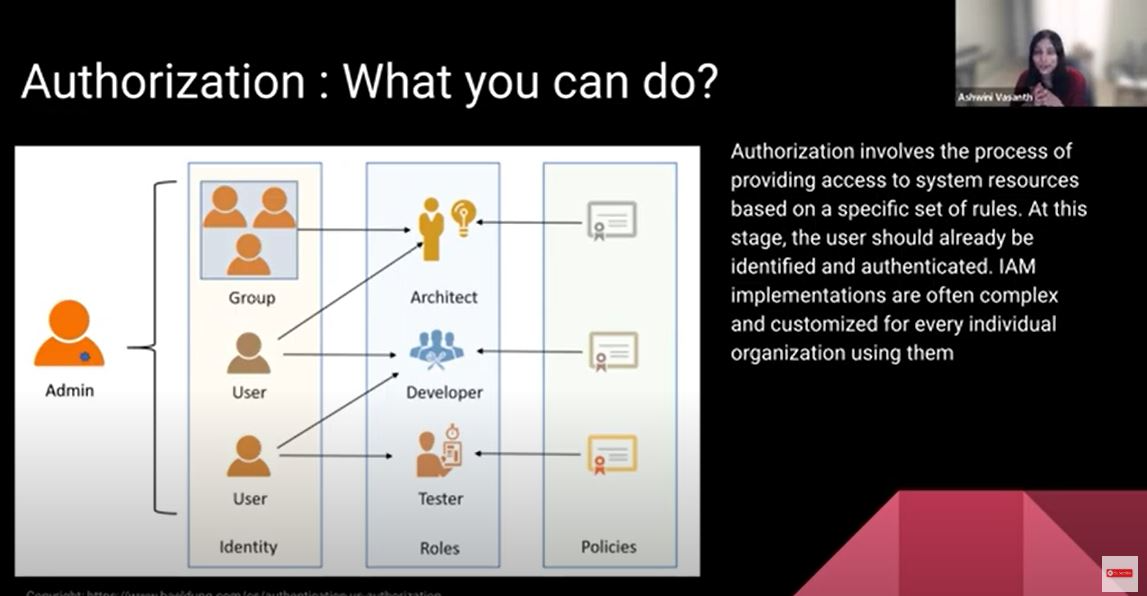
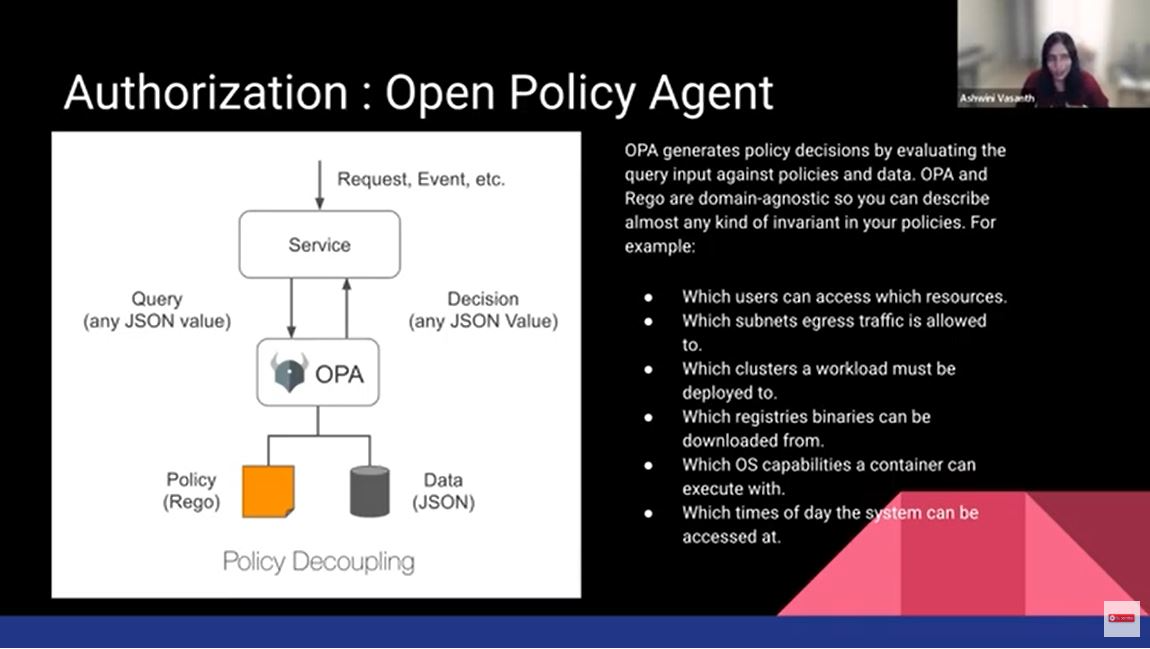
We figured out who you are. We need to see whether we'll give you permission to do everything or restrict it in some way. That's where the authorization piece comes in. Identity could be user one or user two. You could group a bunch of these users that correspond to a role, a role of an architect, a developer, or a tester. To that particular role, you can apply certain policies. This is commonly referred to as role back access control, R back. If your product is built using any kind of service mesh, an open policy agent can be hooked into it. You can send a query and a decision to the open policy agent engine. The engine will have policies written and will figure out whether the access should be allowed or not.
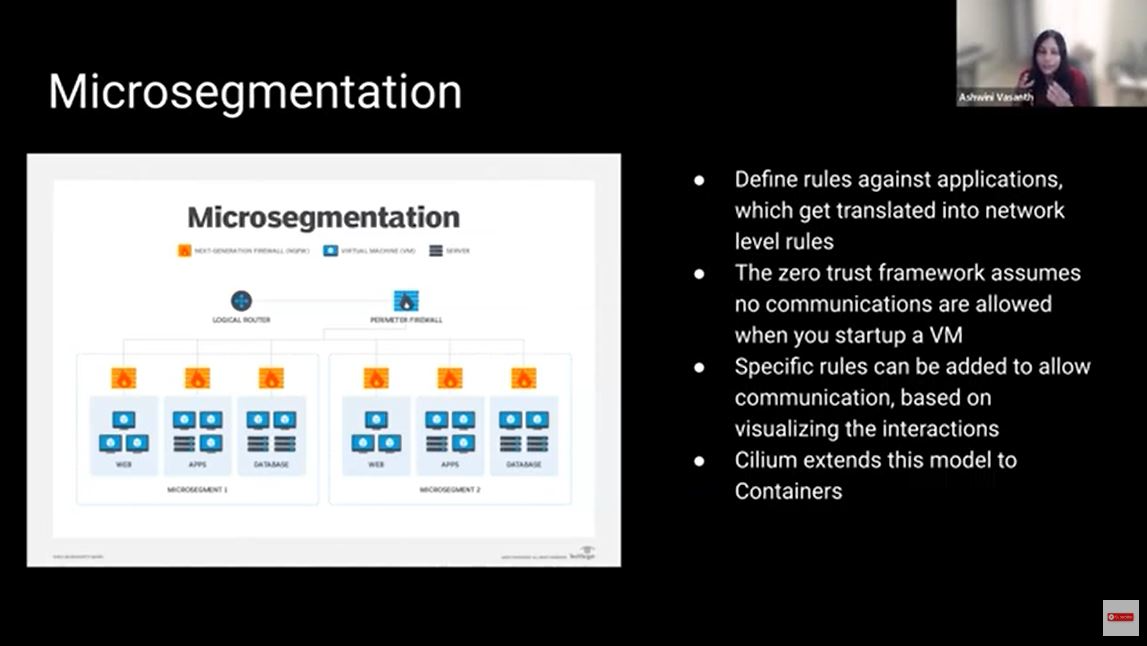
How about the internal services? From the network angle, there is something called micro-segmentation. Micro-segmentation is a way to secure an application. If I wanted to write a rule that my web cannot communicate with the database, micro-segmentation could convert that into corresponding IP addresses and ports and into network rules to make that a reality. The zero trust model is you start by not allowing any interactions and then start gradually allowing the interactions that you actually want to happen.

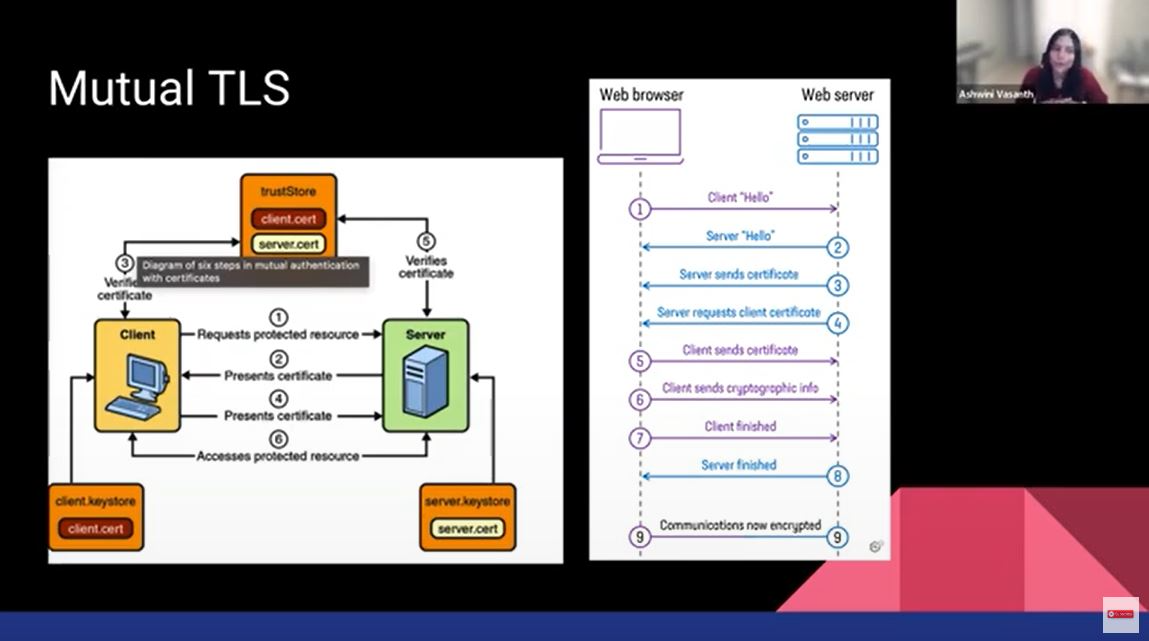
The next rule is to encrypt all communications. To encrypt all of the communication, there is mutual TLS. The client verifies that the server is who the server says it is, and the server verifies that the client is actually who it says it is. Communication is completely encrypted. The other part of encryption is something called data encryption at rest. The data which gets stored in a database needs to be encrypted as well. Encryption happens with some kind of combination of public key and private key. The other piece of database security is that you also need access control when you're accessing information from the database.
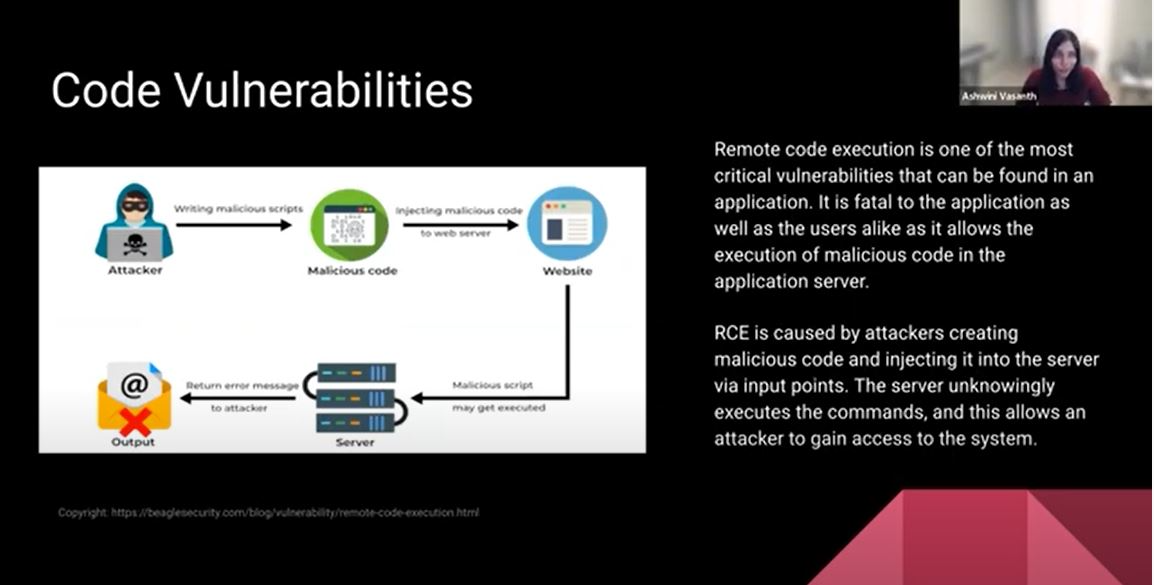
There are vulnerabilities in the code. A lot of the code could be a combination of libraries. Or there is open source code that could have vulnerabilities. One of the most dangerous vulnerabilities is remote code execution. The attacker can actually create malicious code or activity by injecting it through your server. They could run a script to gain access to your system or your network overall and then compromise the system.

What do we do about attacks like that? There's code vulnerability scanning, which is more of a static code analysis that you keep running. You would have a CICD pipeline or some kind of pipeline where your code gets built, deployed, and tested. In that pipeline, you would make sure that you also scan the libraries for vulnerabilities. You could also scan the binaries that you're using. You should apply security patches regularly. This kind of scanning would basically tell you if there's a vulnerability and you need to apply a security patch. It's good to look at the rating of an open-source library. It's also important to check what their security practices are in terms of the frequency of their patching and the engagement by the community.

The other kind of analysis you could do for code vulnerability is something called fuzzing. You determine the inputs to any kind of function or any product or service. You generate data based on the input slope. Fuzzed data is essentially, potentially malicious data. You execute the tests against this data and analyze how the system behaves. Then you start identifying issues based on the behavior and where there are flaws. Going one step further, there is something called pen-testing. You set the goals of how you want the overall intelligence gathered. Then you use scanning tools to understand how the target actually responds to intrusions. You actually launch these web application attacks on yourself. You stage it and you target those vulnerabilities.